
- Summary
- Integrating AI and Machine Learning into Clinical Trials
- 6 Key Use Cases of AI in Clinical Trials
- Conclusion: AI-Powered Clinical Trials Are Here
- External References
Summary
The future of Clinical Research is AI”! It’s commonplace to hear this nowadays, but what does it mean? We have all heard about how Artificial Intelligence is being applied in basic research to identify molecules, find disease patterns in potential patient populations, and in Virtual Trials.
In this article, I will briefly touch upon the various well-known and a few lesser-known applications of AI and Automation in the clinical trials process.
Integrating AI and Machine Learning into Clinical Trials
Machine Learning (ML) is a branch of Artificial Intelligence (AI) that deals with applying algorithms to data, enabling the system to ‘learn’ and improve. ML allows users to process large quantities of data and make smart inferences and predict outcomes. These insights can be used to automate parts of the system, leading to a faster and more efficient clinical trial system.
Automation allows the ML predictions to be fed back into the system and specific actions to be taken, reducing the need for human intervention and improving quality and speed. ML and automation can be applied across every stage of the trial process.
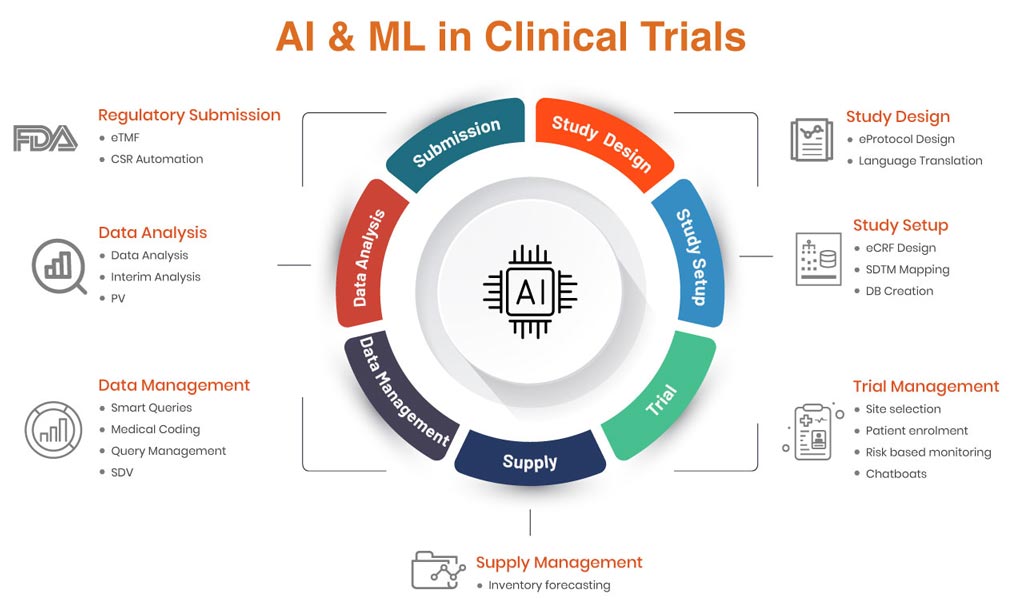
6 Key Use Cases of AI in Clinical Trials
Study Design
Machine Learning can be applied to protocol design and language translation. Using existing protocol data and health libraries for specific therapeutic areas, a protocol for a new study can be generated by the system. The ML algorithms would be able to design an optimal protocol from the knowledge base, leading to reduced design times and protocol amendments, and study disruptions.
Language translation could also be done quickly and easily, and with a greater degree of accuracy than traditional methods, since the ML model would have a domain-specific language knowledge base to learn from.
eCRF Design
ML can be used to automate the design and set-up of the CRF and study database. Using a library of CRFs for specific therapies and study designs, based on the protocol, the ML model can be trained to design an optimal CRF along with edit checks. Automation allows this output to be translated into an actual study setup and validation, allowing database designers to tweak the design as and where required.
This approach leads to an optimal design which also incorporates edit checks that otherwise might be missed out if being designed by a human. Automation also allows this ML-designed study to be set up and validated. The validation report provides the necessary inputs to designers to apply the finishing touches before going live. ML can also be used to automate SDTM mapping or create SDTM-annotated studies.
Trial Management
A lot of automation involving machine learning is possible in trial management. Some of the obvious use cases are site selection, patient enrolment, Risk-Based Monitoring (RBM), and Chatbots.
Site Selection: Optimal site selection is possible using machine learning models. These models can be trained to review site parameters such as Enrolment, Safety, Compliance, and Data Quality, and predict which sites would be good candidates for a new study for a particular specialty. Prioritization of these parameters depends upon the type of trial and CRO/Sponsor.
The algorithm could be trained on previous study data and would be able to predict site performance for a new study.
Patient Enrolment: Predictive Analytics for patient enrolment is a popular use case. This utilizes variables such as therapeutic area, study duration, disease prevalence (from Health Economics), study complexity, adverse events, randomization, multi-centric, etc.
The ML algorithm would review all the above variables and select those that have the most impact (relevant). The finalized model could then be used for future studies to predict patient enrolment. Even though this is a popular use case, the large no of external factors makes this prediction very challenging and of low probability.
Risk-Based Monitoring (RBM): This can be applied at various stages of the trial to identify and mitigate risks affecting a clinical trial. One type of RBM utilizes some of the components of site selection, like Enrolment, Safety, Compliance, and Data Quality, and other variables like therapeutic area, multi-centricity of trials, etc., to predict site performance during a clinical trial.
These predictors can be used to de-risk the trial by identifying risk in advance and working to alleviate it, or closing some sites and opening new ones or focusing on the sites which are doing well.
Chatbots: Chatbots are some of the simplest and easiest to develop examples of the power of machine learning. Different chatbots can be deployed for different types of users – site users, CRO staff, patients, etc. Users can interact with them by text and voice, and the chatbots understand natural language and context and are able to respond with very accurate responses.
Data Management
Data Management offers tremendous scope for AI-enabled automation. Some of them are listed below:
Smart Queries: In smart querying, the machine learning algorithm reads the entered trial data and identifies potential queries that can be raised for various field items. This identification is possible through a combination of previous study data and the therapeutic area.
The algorithm learns the potential value ranges for a particular data point about a therapeutic area and raises a query if it identifies a deviation. This query is then vetted by a data manager and qualified as a legitimate query or discarded. The ML algorithm also learns from this decision and improves its classification going forward.
Medical Coding: Medical coding terms using WHODD and MedDRA dictionaries can be automatically coded using regular programming, only to a certain percentage above which a medical coder has to review the data and manually code the remaining terms.
ML algorithms can learn from coding libraries for various therapeutic areas. They can then match the required verbatim text of the study with the correct dictionary term for that specialty. Machine Learning can accomplish this coding to a high degree of accuracy.
Query Management: Thousands of queries are raised for every clinical trial, and a large amount of time is spent responding to these queries. Many of these queries are redundant and raised because of the misconfiguration of edit checks in the EDC.
These can be identified using machine learning and managed in bulk, or appropriate edit checks can be configured mid-study to address the issue going forward. Machine learning uses clustering to identify clusters of queries that can be grouped and issues identified. These clusters can also be dealt in bulk.
Smart SDV: Organizations spend a lot of time and money on trial monitoring. CRAs must travel to sites to monitor the study and also do Source Data Verification (SDV). Machine learning can greatly reduce all these manual efforts. Site personnel can take an image of the source documents and upload them to the server.
Machine learning algorithms can extract the text from these images and send it to the EDC. The EDC system then compares this data to the entered data and marks them as source data verified if there’s a match. Otherwise, it raises a query that would need to be manually verified.
Data Analysis
Machine Learning can provide many insights into clinical data during and after the trial. Classification, clustering, and prediction are some of the techniques that can be used in data analysis to bring out critical insights into large datasets. Patient behavior, adverse events etc., can be predicted using machine learning.
Regulatory Submission
Regulatory submission in clinical trials requires a large amount of documentation. These can be templatized and automated using machine learning.
CSR Automation: The Clinical Study Report can be generated automatically using machine learning by reading the Study Protocol and the Study Analysis Report (SAR). Following the ICH GCP templates, most of the CSR can be generated. Natural Language Processing (NLP) algorithms can be used to change the language of the clinical study report and can also be used to generate narratives.
These can then be reviewed by the Medical Writer and edited to arrive at the final CSR. All of this is possible in 2-3 days. This process shortens the regulatory submission process drastically and improves submission quality.
Conclusion: AI-Powered Clinical Trials Are Here
AI and automation are no longer future promises; they're actively transforming how clinical trials operate today. By reducing human error, accelerating timelines, and cutting costs across every trial phase, these technologies are making drug development faster and more accessible. The question isn't whether to adopt AI in clinical research, but how quickly organizations can integrate it to stay competitive in modern healthcare innovation.
External References


